JPQL에서 fetch join을 사용한다는 것은 아래와 같이 번역되는 것이다.
SELECT c FROM Comment c JOIN FETCH c.post p
SELECT c, p FROM comment c JOIN post p on c.post_id = p.id;
위와 같이 fetch join을 사용한다는 것은 한 번에 두 객체를 동시에 조회한다는 뜻이다. 즉, EAGER/LAZY 다 상관없이 N+1 상황이 발생하지 않기에 fetch join을 주로 사용하는 것이기도 하다.
근데, 페이징을 구현하면서 fetch join을 함께 사용하면 꼭 문제가 발생하곤 한다. 그래서 이번에는 fetch join과 Pageable 인터페이스를 함께 사용할 때, 어떤 문제가 발생 가능한지 상황별로 알아볼 생각이다.
OneToMany과 ManyToMany 관계에서의 페이징
우선, 페이징을 다루기 앞서 컬렉션 관계를 join하면 어떤 일이 일어나는지 살펴보자.
SELECT Post FROM Post p JOIN FETCH p.comments
위와 같이 OneToMany 관계에서 fetch join을 했다고 가정했을 때, 아래 그림을 보자.

위 그림에서 A게시글만 조회하는데, 댓글들도 모두 가져오고 싶다고 가정해 보자. 우리가 기대하는 것은 1,3,4 댓글을 하나씩 가져오는 것이다. 하지만 아래 그림을 보자.
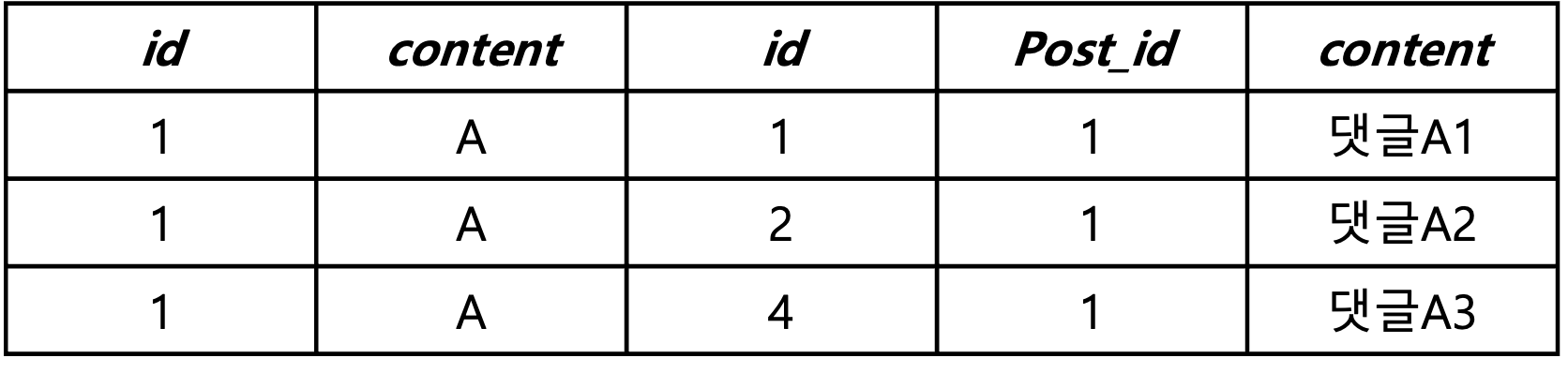
위와 같이 JPA에서 3줄을 조회하는데, 영속성 컨텍스트에는 1이라는 id로 하나의 객체가 생성될 것이다. 하지만, JPA에서 조회한 데이터는 3개이므로 post들이 하나의 객체를 참조하여 총 세 개의 결과가 나온다.
즉, fetch join은 엔티티 그래프를 참조해서 모든 데이터를 가져오고 애플리케이션에 같은 id를 가진 엔티티 중복을 제거해야 한다.
서론이 길었지만, 이러한 매커니즘을 이해하고 보면 사실상 컬렉션 관계를 fetch join 하여 페이징 한다는 것이 불가능하다고 보는 게 맞다. 일대다 테이블을 조인하면 데이터의 수가 변하기 때문이다.
fetch join이 아예 불가능한 것은 아닌데, fetch join을 사용하여 페이징을 한 경우 아래와 같이 로그가 남는다. 모든 데이터를 불러와서 메모리에서 페이징을 적용학 때문에 OOM을 우려하여 경고가 발생하는 것이다.
아래는 예시이다.
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Post{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long postId;
private String user;
@OneToMany(mappedBy = "post")
private List<Comment> comments = new ArrayList<>();
private String title;
private String content;
public Post(String user, String title, String content) {
this.user = user;
this.title = title;
this.content = content;
}
}
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long commentId;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "post_id", nullable = false)
private Post post;
private String content;
public Comment(Post post, String content) {
this.post = post;
this.content = content;
}
}
public interface PostRepository extends JpaRepository<Post, Long> {
@Query(value = "SELECT p FROM Post p JOIN FETCH p.comments WHERE p.postId = :postId",
countQuery = "select count(p) FROM Post p join Comment c on p.postId = :postId")
Page<Post> findAllWithComment(Pageable pageable, @Param("postId") Long postId);
}
실행 결과

- 위 문제를 해결하기 위해선 batch size를 설정하는 등의 방식들이 존재한다.
그런데, Hibernate6부터 바뀐듯하다.. 겁나게 테스트 했는데 이상해서 좀 찾아봤더니 공식문서에 아래와 같이 나와있다.
Starting with Hibernate ORM 6 it is no longer necessary to use distinct in JPQL and HQL to filter out the same parent entity references when join fetching a child collection. The returning duplicates of entities are now always filtered by Hibernate.
대충 번역기 돌리면 아래와 같이 나온다. ”더 이상 JPQL 및 HQL에서 distinct를 사용할 필요가 없습니다. 반환되는 엔티티의 복제본은 이제 항상 Hibernate에 의해 필터링됩니다.”
아오..
Fetch Join과 Paging 그리고 CountQuery
페이징을 하기 위해선 당연히 전체 page 수를 알아야 하기 때문에 카운팅 할 데이터의 전체 수가 있어야 한다. JPQL을 사용하기 위해 @Query() 속성 안에 countQuery라고 있다. 여기에 작성하면 된다.
이걸 작성하지 않으면 임의의 JPA가 생성하는데, 이 생성하는게 참 단순한 것 같다.. 그래서 문제가 발생한다. 아래 예시를 살펴보자.
@Entity
@Table(name = "users")
@Getter
@AllArgsConstructor(access = AccessLevel.PROTECTED)
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long userId;
private String email;
private String name;
private int age;
public User(String email, String name, int age) {
this.email = email;
this.name = name;
this.age = age;
}
}
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Post{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long postId;
private String user;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id", nullable = false)
private User user;
private String title;
private String content;
public Post(String user, String title, String content) {
this.user = user;
this.title = title;
this.content = content;
}
}
public interface PostRepository extends JpaRepository<Post, Long> {
@Query(value = "SELECT p FROM Post p JOIN FETCH p.user")
Page<Post> findAllWithUser(Pageable pageable);
}
- Post와 User는 다대일 관계이므로 정상적으로 fetch join을 사용하여 paging을 할 수 있다.
- findAllWithUser()을 통해 페이징 조회를 한다.
findAllWithUser()를 보면 아무 문제가 없어 보이지만 아주 심각한 문제가 있다. 우선 실행시키면 아래와 같은 에러 메시지가 나온다. ”org.hibernate.QueryException: query specified join fetching, but the owner of the fetched association was not present in the select list”
대충 연관된 부모가 select list에 없다는 뜻이다.
그렇다면, 왜 위와 같은 에러가 발생하는지 살펴보자.
findAllWithUser()을 호출하면 당연히 페이징 조회이므로 카운트 쿼리가 발생해야 한다.
자체적으로 JPA가 생성하는 카운트 쿼리는 아래와 같다.
select count(p) FROM Post p JOIN FETCH p.user
- 위와 같이 카운트 쿼리가 발생한다. 문제가 없어 보이지만 “FETCH” 라는 키워드가 아주 큰 문제이다.
fetch join은 엔티티 그래프를 참조하고 조회하는 기능이다. 그렇기 때문에 연관된 부모가 당연히 select list에 있어야 하는데 지금 보면 카운트를 하겠다고 count() 함수를 쏙 박아놨다.
당연히 오류가 발생한다. 즉, fetch join 과정에서 문제가 발생한 것이고 이를 방지하기 위해 countQuery를 분리하여 아래처럼 직접 명시하면 될 것이다.
public interface PostRepository extends JpaRepository<Post, Long> {
@Query(value = "SELECT p FROM Post p JOIN FETCH p.user",
countQuery = "SELECT count(p) FROM Post p")
Page<Post> findAllWithUser(Pageable pageable);
}
그런데,,,!!!! 같은 팀원 분이 countQuery를 명시하지 않고 fetch join과 함께 paging 조회를 성공 하셨다고 한다. 코드를 살펴보니 나와 다를 게 하나도 없었고, 이유를 알아보고자 프로젝트를 새로 파서 6~7시간 디버깅을 시작했다.
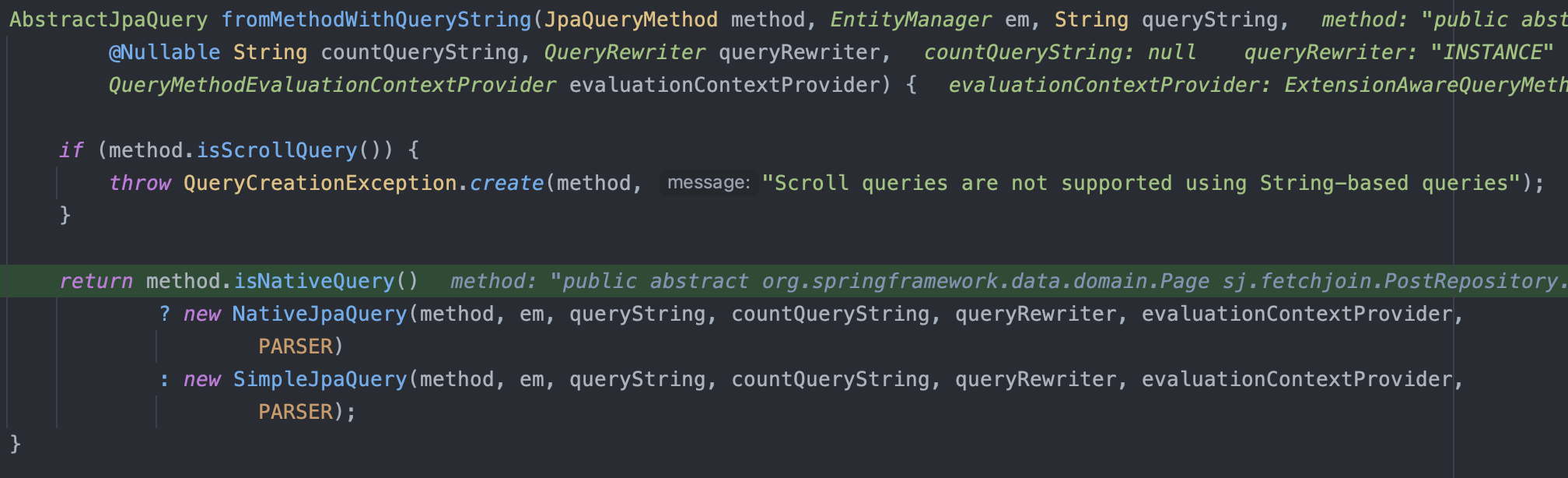

- 작성한 JPQL을 문자열로 하여금 SQL로 변환하는 로직의 시작부분인것으로 보인다.


JpaQueryLookupStrategy를 지나, AbstractStringBasedJpaQuery 에서 위와 같이 카운트 쿼리가 나오는 것을 확인할 수 있다.
그런데 마지막 부분이 의문이었다.
분명히 내가 제출한 미션 코드에서는 "select count(p) FROM Post p JOIN FETCH p.user"라고 countQuery가 자동생성 되어서 에러가 발생했는데??_??
그래서, 다시 내 프로젝트로 가서 살펴보았다. 계속해서 "select count(p) FROM Post p JOIN FETCH p.user"라고 생성되어서 디버깅을 해보니 정리된 내 생각은 Hibernate6으로 되면서 SQL을 생성하는 방식의 변화가 생긴 것 같다. 겁나 허무하다. 끗..!
+) 뭔가 영한님 강의 커뮤니티에 나랑 비슷한 상황의 글이 있을 것 같아 찾아보니 역시였다.
댓글로 “hibernate6으로 업그레이드 되면서 내부 파서에 큰 변화가 있었습니다.”라고 정리해 주셨다.
공식문서 찾아도 잘 안 보여서 헤매었는데,, 아직 내공이 부족한 듯하다.ㅎ
요 강의는 안 들어봐서 몰랐는데,, 들어보면 좋을듯하다ㅎ
https://www.inflearn.com/questions/886858/스프링-데이터-jpa-페이징과-정렬-left-join-쿼리
'backend > Spring' 카테고리의 다른 글
| 빈번한 북마크 update요청을 방지하기 위한 사용자별 스레드 관리 (0) | 2023.09.13 |
|---|---|
| 무한 스크롤 구현 및 성능개선 (Pagination) (0) | 2023.09.13 |
| [Spring] 스프링의 DI를 이용한 전략패턴 도입 (0) | 2023.06.08 |
| [JPA] 동일 트랜잭션 내 OneToMany 필드 객체의 데이터와 DB 데이터의 불일치 (0) | 2023.04.21 |
| [spring] @Configuration의 프록시 객체 (0) | 2023.03.10 |



